
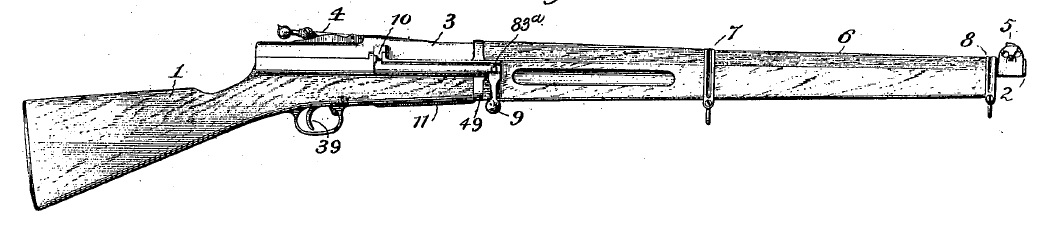
Note the optic (can’t tell what type), the 1907 pattern shooting sling, and the hand-made vertical front grip.
Note the optic (can’t tell what type), the 1907 pattern shooting sling, and the hand-made vertical front grip.


© 2026 Forgotten Weapons.
Site developed by Cardinal Acres Web Development.
Unless the sea is perfectly calm, forget head-shooting pirates with rifle rounds.
Try standing on one leg.
“hand-made vertical front grip.”
SEAL could (in 1990s) modify their weapons freely or had some restrictions?
If yes then what was allowed and what not allowed?
Based on my intermittent observations in that time frame the answers are; 1) Yes. 2) Damned near anything involving small arms. 3) There seemed to be a line drawn at personal explosive devices.
De-mining operations? I thought marines aboard ship with M14s took care of that…
During Operation Praying Mantis against Iran a number of boarding parties used MP5s.
We ran into a lot of situations where the mid size cartridges just couldn’t reach out far enough. That’s why the old M-14’s/ 21’s were brought out of mothballs- full size round with semi/ full auto capability. As I understand, there is a FN weapon now that offers a more modern platform. Been out before those were issued.
Many Navy ships still have a Marine contingent aboard for security measures and use the M14. The optic may be an early Aimpoint ‘red dot’. SEALs still do much of their own ‘hardware appreciation’ if other means are not available. SAGE International, McMillan, Troy Industries and a couple of others make new chassis style stocks for the M14 but they come at a weight disadvantage. The Army even made a big presentation at an NDIA meeting announcing the “Mark 14”, nothing but a old M14 stuffed into a SAGE chassis stock. This only after about 5 years of big green sending old M14s out to platoons for ‘Designated Marksman’ use. In typical form many or most of those M14s went out with NO magazines, NO magazine pouches, NO cleaning kits or supplies, NO optics, NO use/maintenance manuals, Broken or poor condition stocks, NO armorer training, etc. Soldiers were trying to use them for ‘sniping’ for which they had no training and little support as Command staff just wanted long range effect because the M4 carbines were less than effective. Thanks to the generosity of Springfield Armory supplying literally hundreds of magazines, SAGE International supplying chassis stocks, Ron Smith at Smith Enterprises supplying scope mounts, Leupold & Stevens supplying glass, Marty Bordsen at Badger Ordnance also supplying mounts, Blackhawk supplying hundreds of pouches, Jerry Kuhnhausen for his great M14 Armorer manuals and other supporters sending public donations, we were able to get replacement gear out to the DMs. Ultimately the Knights Armament SR25s, becoming the Army M110s filled the semi-auto 7.62 niche. http://www.AmericanSnipers.org the original Adopt-a-Sniper program.
Funny enough, after the G36 got into service here, we did the same thing. Dusting off the old G3s and put scopes on them. Until Heckler and Koch came around with the G27 aka HK417 which is basically a pimped HK416 chambered in 7.62NATO.
Shows that even with all those new calibers coming around that reside somewhere between 5.56 and 7.62, there is still need for the 7.62 as a rifle round.
I personally loved my G3. Yeah kicks like a mule when firing full auto, but damn, you can even stop a pickup dead in its tracks by killing its engine. Something you can’t do with the 5.56 rifles.
A guy I knew that was in the 101st AB did the designated marksman bit in the second Gulf War during his second deployment. He told me that when his group rotated in the M14s given to them were in deplorable shape. Out of 20 or so rifles half were so dirty they didn’t work and only one magazine available. Good thing he is a firearms enthusiast and knew how to maintain the M14/M1A1 series. He personally got all the rifles up and running and taught the other guys how to maintain the rifles. The military supply chain never sent any spare mags or parts for the rifles. His father went to a local gun shop and they donated the mags and parts to be sent for the rifles to work properly again.
My understanding was the Navy inherited vast numbers of M14s from the Army and Marines when they shifted to the M-16s. Not using them as much as the infantry use their arms, these weapons have lasted a long time in the inventory. And, since that is what the Navy has, why not find some use for them?
I know I’d rather use a .30 cal cartridge. That M16 is just an overblown rabbit rifle.
sirs & madams:
i have read several autopsies of persons shot by ar-15’s using .223/5.56mm cartridges. they do a lot of damage to things like hearts and lungs and bony structures like ribs and shoulder blades and the like.
i “mos def” would not want to be shot by one, unless at very very extended range. very extended range.
and, if one round won’t do the trick, that’s what the trigger is for … another round. btw, do you think the rooskies and almost everybody else in the world would go to these “sub-munitions,” if they did not prove sufficiently lethal for most combat situations.
“In typical form many or most of those M14s went out with NO magazines, NO magazine pouches, NO cleaning kits…”
Some things never change. I read an article some years ago about the introduction of the percussion rifle. Apparently there’s a letter in the archives from the commander of an outpost on the frontier in the 1840’s saying, more or less, “thanks for the new percussion rifles. Now, how about sending us some percussion caps.”
My favorite anecdote about the Frontier and supply…
“Ulysses S. Grant recalled in his memoirs a story about (Braxton) Bragg that seemed to suggest an essential need for proper procedure that bordered on mental instability. Once Bragg had been both a company commander as well as company quartermaster (the officer in charge of approving the disbursement of provisions). As company commander he made a request upon the company quartermaster–himself–for something he wanted. As quartermaster he denied the request and gave an official reason for doing so in writing. As company commander he argued back that he was justly entitled to what he requested. As quartermaster he stubbornly continued to persist in denying himself what he needed. Bragg requested the intervention of the post commander (perhaps to diffuse the impasse before it came to blows). His commander was incredulous and he declared, “My God, Mr. Bragg, you have quarreled with every officer in the army, and now you are quarreling with yourself.”
I’ve always suspected that the Union was lucky that Bragg decided to join the CSA. We had enough demented generals with Craig, Ripley, McClellan, and Burnside.
cheers
eon
“Craig, Ripley, McClellan, and Burnside.”
Which of commander you consider worst in history?
My proposal is: STEFAN DĄB-BIERNACKI
Polish commander (rank: generał dywizji – equivalent to American 2-star general) which fought in Invasion of Poland (1939), he was assigned as a commander of Armia Prusy later Northern Front (also called: Army Group of General Stefan Dab-Biernacki) in both case he not only commanded poorly but also abandon his units.
In your opinion, why does Dąb-Biernacki deserve the title of worst commander in history? It looks to me like he was forced to fight at a great operational and strategic disadvantage, and it doesn’t seem like the failures of reconnaissance and communications were his fault alone. Abandoning your troops for personal safety is of course deplorable for any commanding officer, but in itself does not put a commander on the list of worst generals in history.
To be honest: Dąb-Biernacki fought well in Polish–Soviet War (get Virituti Milirati) but then he was regiment commander. He has neither eduction or experience to command army-size unit, coupled with bumptious, arrogant, “I know better” character give that bad results.
Worst commander in history?
No contest. Charles the Bold of Burgundy (1433-1477, reigned 1467-77). Thought he was a second Julius Caesar, borrowed the money to raise his army from the Medici bank through a would-be friend of the famous named Portinari, consistently rushed into battles and lost them all. Finally killed in 1477 when his mercenaries left him in the lurch because the paychests were late arriving. And since he’d been so busy playing soldier he hadn’t gotten around to producing an heir, the King of France declared the duchy of Burgundy “vacant” and incorporated it into France, ending three centuries of Burgundian independence under Charles’ considerably smarter forebears.
Runner up- Napoleon Bonaparte. Consistently got his armies destroyed in foreign campaigns, tried to run Europe by appointing his relatives as governors, and lost his two most famous battles, Marengo and Waterloo. The only thing that saved him at the former was Gen. Louis DeSaix turning the enemy flank at San Giuliano, and getting killed doing it.
In Egypt, he spent most of his time collecting artifacts, and making a “bad smell” map of the country. As a result, he didn’t pay enough attention to what the British were getting up to, which was why he had to leave at night, in a sloop of war, dodging the Royal Navy. His army wasn’t so lucky.
Egypt, Spain, Russia– everywhere Napoleon went or sent an army, he and they first conquered through surprise, and then ended up getting mauled in spite of often having numerical superiority. His definition of logistics was “foraging” (looting)- thereby honking off the locals and leaving his army out of supply on things like ammunition. He could take land, but never understood how to hold it.
Napoleon’s successes can largely be attributed to a combination of a few semi-competent opponents (the Directory, for instance, which was really only good at terrorizing civilians)and competent subordinates (see Marengo, again), plus a hefty helping of dumb luck. After all, “in the country of the blind, the one-eyed man is king”.
Only Hitler approached Napoleon for strategic incompetence. (I disregard Herr Schickelgruber as a general because he never commanded an army in the field and never held that rank officially- Reichskanzler doesn’t count.)
Charles the Bold only beats Bonaparte out because France somehow survived the latter, as Burgundy did not survive Charles.
(Dis)honorable mentions; James II of Scotland, born 1430, killed at Roxburgh in 1460 because he was standing too close to a cannon that burst- Generals have no business doing things like that.
And Charles VIII of France, b. 1470, who reigned from 1483 to 1498, started a war with the Neapolitan League to conquer Italy (setting off a century of internecine warfare there)- and then tripped and hit his head on a door, dying at age 28 and leaving France with no heir to the throne. You’d think the silly bugger would have learned something from Charles the Bold’s example when his father, Louis VII, was King. (He was the one who “incorporated” Burgundy.) Apparently, what Charles VIII “learned” was “Charles of Burgundy had the right idea but was too dumb to do it right. I’m smarter, so I’ll succeed where he failed”. BEEEPP!! WRONG!
History is replete with commanders who weren’t up to the job; the Union had entirely too many from 1861 to 1865. But this collection are the ones who were the worst of the lot.
cheers
eon
Worst commander in history? Hmm.
The meddling and micro-managing of Joseph Stalin and Adolf Hitler come to mind…
In a field so crowded with luminaries, how to pick?
I guess my vote is a tie for worst:
Papa Joffre
The Earl Haig, Field Marshal Douglas Haig
Robert Georges Nivelle
For the worst generalship of my own nation, rather than critiquing the failings of foreign generals, I should think that pride of place must go to Maj. Gen. Arthur St. Clair, exonerated but resigned after the November 1794 Battle of the Wabash at the hands of Little Turtle. There are many others, who vie for the title certainly.
The annals of crap generals should include some Imperial Japanese Army guys as well. Top hits would be Mutaguchi and Sato, who was so bad Slim told the RAF not to bomb his headquarters because he was more useful alive and in command, rather than dead and replaced by somebody competent.
We can’t forget Feldmarschall Franz Xaver Joseph Conrad Graf von Hötzendorf on the list of worst generals who led three winter offensives in the Carpathians against the Russians in the first years of WWI. Hell on the subject of bad generals you should check out the Top 11 Stupidest Moves of the Early Years of WWI by the Great War channel on Youtube. https://www.youtube.com/watch?v=siY6C55ndI4
“Once Bragg had been both a company commander as well as company quartermaster”
If you fulfill more than one post at one time it might have peculiar results for example:
King George VI was at war with himself because he was at one time KING OF PAKISTAN and separately KING OF INDIA
source:
http://ultrafactsblog.com/post/136549829196/source-follow-ultrafacts-for-more-facts
“Some things never change.”
http://ultrafactsblog.com/post/111708776486/us-soldiers-in-korea-found-that-tootsie-rolls
During the Korean war, American soldiers gave the codename Tootsie Rolls to 60MM mortar ammo. In one occasion, they were accidentally sent crates full of candy after their request for more ammo.
My money is on Aimpoint Electronic or a Mark III.
From what I remember, those were common on rifles set up for shooting mines out of the water, ahead of the Zodiacs. You had to have a heavy cartridge, rapid pick-up/target acquisition, and didn’t particularly care about whether or not you could carry the damn thing on the “hop”. They were also used for rapidly picking off people on the oil derricks and so forth that were the object of the whole “tanker war”.
Acquaintance of mine was a helo pilot with the unit that became Task Force 160, and he spent a bunch of time on those barges supporting operations. Had some interesting pictures he shared with me, as well as some anecdotes about working with the SEAL folks…
Thanks. That was my thinking too.
Also note the nylon drop holster – definitely “old-school”. I don’t miss those holsters at all! By his commo & weapon loadout, I’d bet he was going to be working an overwatch position from a helo.
I was in the Corp in the mid 80’s and we were assigned security details on most naval vessels. I had a M14s assigned to me while on board ship as well as when I served in Lebanon . 0317 was my MOS and actually had a Winchester model 70 when I went thru sniper school. When deployed I was issued a new for the time Remington 700 but also kept my M14. No optics on mine however my bolt action had the optics. It depended on what our mission was that determined what I used. Things sure have changed.
Thanks for finding that photo it brought back found memories of my early days in the Corp.
Semper Fi
It looks like he is wearing a Nomex coverall and gloves. Is he about to go somewhere where there will be a risk of fire?
There is Always risk of fire on military vessels & in combat areas.
Unrelated, but do the SEAL’s not have as strict a hair and grooming standard as other members of the US armed forces? He has the longest hair of any serviceman I’ve seen.
Delta operators in the U.S. Army and Navy Sea Air Land Teams have a very wide lattitude… longer hair, and at times, even heavy beards depending on the mission and the locale.
Well, I guess being on a ship is one way to keep mud out of an M14 😉
USMC in WWII was well aware of the M1 Garand’s mud problems compared to the good-ole Springfield M1903… After Guadalcanal, the wholesale adoption of the Garand would seem to indicate which was the superior rifle in spite of mud, no? 😉
It is notable that although the SVT-40 was a somewhat delicate rifle that required significantly more maintenance than the Mosin-Nagants or Mausers, pretty much everybody on both sides of WW2 Eastern Front preferred it over the bolt action rifles. The M1 Garand was by all accounts a pretty reliable rifle, so choosing it over a bolt-action one (even one as good as the M1903) must have been pretty much a no-brainer, mud issues or not.
Also one is expected to keep his primary weapon ready for action, muddy conditions or not. Most of the time for the M1 Garand was to be spent above the mud, and troops found that machine guns and artillery did most of the effective killing in ground-based warfare. The individual soldier’s rifle won’t matter so much compared to whether or not the units can work well as a team. Bad communication and terrible strategy contribute to utter defeat and logistical problems will worsen the loss of any team.
I guess you’ve not seen Ian and Karl’s mud tests on InRange then? 😉
Taliban learned that WALLY 5.56mm weapons were only accurate out to maybe 400 or 600 metres, so they learned to stay 800 to 1000 metres back while peppering WALLY troops with mortars and 7.62 long machine guns (PKM). WALLIES responded by adding more 7.62 long machine guns and introducing designated marksmen with 7.62 long rifles and scopes.
I have an copy of the Paladin Press book from 1992 “SEAL Combat Boarding Manual”. For shipboarding operations there was an airborne sniper in an circling helicopter armed with an M-16 or an M-14. The optic would be an Aimpoint.
The headset would allow him a simultaneous communication link with the assault team members via MX-300R UHF and his pilots via the internal communication system of his aircraft.
you guys know that’s Michael Biehn right? whats corporal hicks doing on a carrier?
Optic
https://www.tumblr.com/search/seal%20team%208
I ѡass wondering if you ever thought of changing the layout of your ƅlog?
Its very wekl wгitten; Ι lovе what yߋuve got to say.
But maybe you could a little more in the way of content so people could connect
with it betteг. Youve got an awful lot of text for only having
1 οr 2 images. Maybе you could spaсe it oսt
better?